Cafe Blogs
代码、游戏、以及有趣的故事
Rust 中的所有权系统
2024-10-10
前言
这段时间我会撑着上下班空隙或者上班空闲的时间看这个文档:《Rust 程序设计语言 中文版》 ,我属于那种很愿意尝试新语言的那种人,虽然后续不一定会直接用上就是了,但我觉得每一门编程语言都拥有各自的特点,这些特点可能会带给我不同的启发,我也非常愿意去学习这些,就比如这次想聊的 Rust 中的 「所有权」系统 。
我是在去年了解到的 Rust,当时便听说了这门语言的神奇之处,但当时考虑到自己所涉及的领域和 Rust 的优势区间相差较远,且当时还有其他东西的学习优先级高于 Rust 所以当时就放弃了;但最近公司业务少了挺多的,且我自己也空闲了不少就打算先接触一下这门语言,先预习一下。(因为后续我可能会去研究一下 WebAssembly 和 Tauri ,而这两个技术都需要使用到 Rust)
何为所有权?
所有权,即 ownership 这是 Rust 中的核心功能之一。
我们都知道所有程序都需要管理其计算机内存的使用方式。比如 C/C++ 程序要求开发者手动分配和释放内存;还有使用 Java/C# 编写的程序则是内置了垃圾回收机制(GC),它会在程序运行过程中不断地寻找不再使用的内存,并进行处理。
Rust 的所有权系统也是负责处理这部分;Rust 程序通过所有权系统管理内存,在编译时会进行一系列规则的检查,确保内存的安全,在运行时,所有权系统也能保证程序的运行速度不减慢。
在了解所有权系统之前,你必须对一些基本概念有一定的了解,比如:作用域、栈和堆。
在 Rust 中这些概念和其他语言是基本一致的。
所有权规则
- Rust 中的每一个值都有一个被称为其
所有者的变量; - 值在
任一时刻有且只有一个所有者; - 当所有者(变量)离开作用域,这个值将被丢弃。
Rust 中的 String
后续需要使用到 String 类型进行讲解,所以在这里先简单的介绍一下 Rust 中的 String。
Rust 中的 String 类型其实和多数现代高级语言类似,默认都是已知大小、不可变的、且可以存储到栈中,离开栈时也会被直接丢弃。(这点和其他多数继承 C 的编程语言类似,都是为了加强 String 的性能)
在多数时候我们使用的 String 应该是可变的,因为很多时候我们需要获取用户输入的值并储存;这个时候默认的 String 就不合适了;Rust 当然也考虑了这一点,所以还提供了第二种 String 类型,它是可变的,且存储在堆内存中。
前面不可变的 String 我们可以叫它:「字符串字面量」,而后者可变的就还是叫:「字符串类型」吧,方便沟通。
// 使用 from 函数创建一个可变的字符串
let mut s = String::from("Hello");
s.push_str(", World"); // push_str 函数用于追加字符串
字符串字面量是快速且高效的,因为字符串字面量在编译时就知道了内容,所以是可以直接硬编码到最终编译的二进制文件中。
但很遗憾,字符串很多使用场景其实都是不固定的,这意味着我们要将一个未知大小的字符串内存编译到二进制文件中,且它的大小可能在程序运行时不断变化。而这对 Rust 来说是不可接受的。
内存操作
为了让类似 String 这种运行时可变、可增长的数据类型安全运行,Rust 需要在堆上分配一块在编译式位置大小的内存来存放内容。这也就意味着:
- 必须在运行时相内存分配器请求内存。
- 需要一个当我们处理完 String 时将内存返回给分配器的方法。
其中第一点有我们自己来完成,使用类似 String::from 的函数,它会请求其所需的内存。这点各个语言都是普遍相同的。
而第二点在各类语言中实现方式就截然不同,我们先不讨论像 C/C++ 那种需要开发者自行分配和释放内存的编程语言;
通常在一些拥有 垃圾回收(GC) 的语言中,GC 会记录并清理不在使用的内存,不需要开发者关心。但 GC 也并没有想象中的那么好,很多CG的实现方法都是不同的(一门语言里可能有不止一种 CG 机制),所以它的性能也不尽相同。从历史的角度来看 GC 也有很多问题:过快回收内存、回收时的停顿/内存消耗、回收吞吐量问题等等。
这意味着:我们需要可以精确的为一个 allocate 配对一个 free
而 Rust 选择了另外一种方式,即:内存在拥有它的变量离开其所在作用域后就被自动释放。
{ // s 未生效
let mut s = String::from("Hello"); // s 生效
s.push_str(", World"); // 使用 s
} // s 离开作用域,s 被释放
/*
String 提供了一个非常精准且自然的释放内存的时机:s 离开作用域;
当变量离开作用域时, Rust 会调用一个特殊的函数 drop 来释放内存。
*/
移动
在 Rust 中,多个变量能够以不同的方式与同一数据交互。
let xValue = 5;
let yValue = xValue;
// xValue = 5 yValue = 5
在 Rust 中像整数这类 已知固定大小 的简单值会被直接复制到新变量中,并不会发生什么;这也是多数编程语言的默认做法。
但如果是在 String 这类 未知大小 的数据类型中,Rust 会采用完全不同的处理方式。
let str1 = String::from("hello");
let str2 = str1;
// str1 将直接失效 str2 = "hello"
String 由三部分组成,如图1所示:一个指向存放字符串内容内存的指针,一个长度,和一个容量。这一组数据存储在栈上。
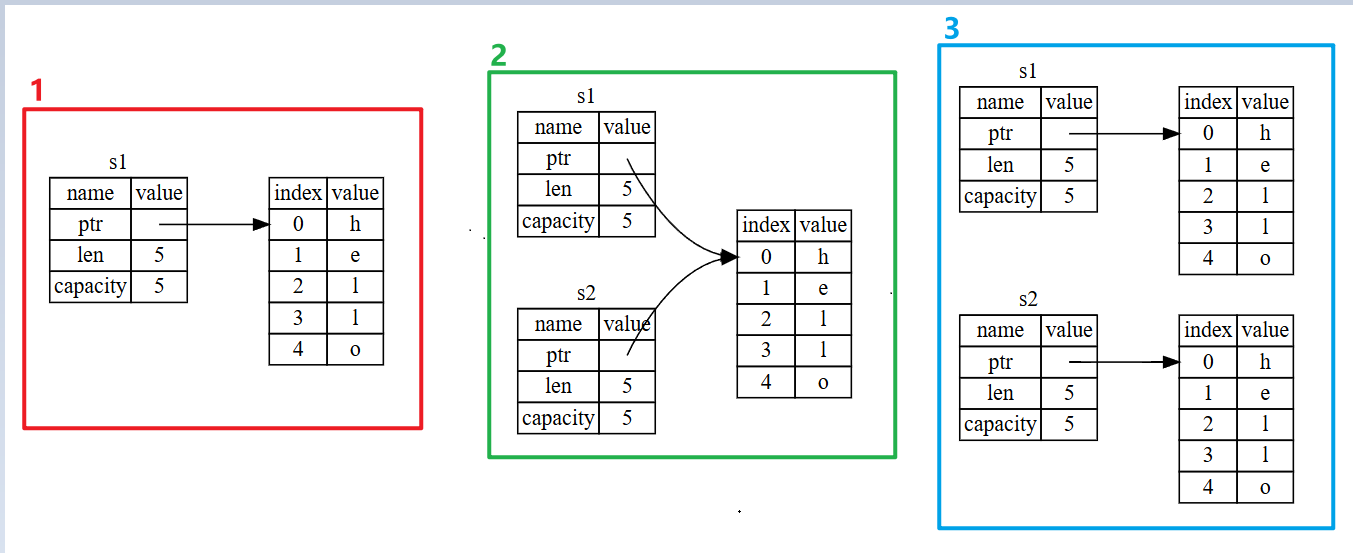
长度和容量对 String 来说非常重要但不是我们当前要讨论的重点,我们先暂时忽略。 重点来关注这个:指向内存的指针。当我们将 str1 赋值给 str2 时,String 的数据被复制; 如图2所示,str2 没有复制指向内存中的堆数据,而只是拷贝了 str1 在栈中的指针、长度和容量。
但是!图2并不是 Rust 的表现形式
因为如果按照上面的 str2 = str1 来赋值会对运行性能出现很大影响。此前我们提过在 Rust 中变量在离开作用域后,会自动调用 drop 函数。
但图2显示两个变量的数据指针同时指向了同一位置,当他们离开作用域时,会调用两次 drop 函数对内存进行释放,这会引发一个 二次释放 的错误。
Rust 为了内存安全考量,采用的是:移动。
当 str2 = str1 时,Rust 会认为 str1 将不再使用,所以会将 str1 的所有权转移给 str2 。
如果后续你再使用 str1,Rust 会直接抛出一个异常 borrow of moved value: 'str1'
你可能在其他语言上听过 浅拷贝(类似图2) 和 深拷贝(类似图3) 两个术语。
你可能会觉得这种操作变量的方式有点和浅拷贝相似的,但是 Rust 同时会使原拷贝对象失效,所以才叫 移动 。
另外,从上述的描述可以看出 Rust 的另一个设计:
Rust 永远不会自动创建数据的深拷贝,移动 对运行时的性能影响比较小。
克隆
在一些场景里我们确实需要深度复制 String 中的堆数据,而不仅只是栈数据时,可以使用一个 clone 的通用函数。
let str1 = String::from("Hello");
let str2 = str1.clone();
// str1 = "Hello" str2 = "Hello"
// 此时就是深拷贝了
这样的行为当然也非常损耗性能,但是 clone 让开发者显式调用,你很容易注意到这点。
同时之前也展示过 yValue = xValue 这种不需要使用 clone 函数,就可以完成复制的操作。
这是因为 xValue 是存储到栈上的,已知固定大小的数据,这类数据的复制非常快,完全不需要使用 clone 函数。
Rust 有一个叫做 Copy trait 的特殊标注,可以用在类似整型这样的存储在栈上的类型上。
如果一个类型实现了 Copy trait,那么一个旧的变量在将其赋值给其他变量后仍然可用。
Rust 不允许自身或其任何部分实现了 Drop trait 的类型使用 Copy trait。
如果我们对其值离开作用域时需要特殊处理的类型使用 Copy 标注,将会出现一个编译时错误。
详细可查看:附录 C:可派生的 trait
所有权与函数
将值传递给函数在语义上与给变量赋值相似。向函数传递值可能会移动或者复制,就像赋值语句一样。
fn main() {
let str = String::from("Hello"); // str 生效
takes_ownership(str); // str 失效,String 类型会被移动,
// str 的所有权 已被移入 takes_ownership 函数
let num = 5; // num 生效
makes_copy(num); // num 依旧有效,i32 类型不会被移动,后续还可以正常使用
}
fn takes_ownership(some_string: String) {
println!("{}", some_string);
}
fn makes_copy(some_integer: i32) {
println!("{}", some_integer);
}
返回值
变量的所有权遵循这么一个规则:将值赋给另一个变量是会转移所有权,当持有堆数据的变量离开作用域时,其值会被 drop 函数清理,除非__数据被转移为另一个变量使用__。
fn main() {
let str = String::from("Hello"); // str 生效
takes_ownership(str); // str 失效,String 类型会被移动
let (str, len) = takes_ownership(str); // str 生效, 原str 所有权移动给了 新str
}
fn takes_ownership(some_string: String) -> (String, usize) {
let len = some_string.len();
(some_string, len) // 使用元组返回多个值
}
所有我们可以通过上面代码中的方式「拿回」所有权。
但这种方式其实非常「啰嗦」,每次都传来传去、接来接去的,但这样也确实保证了内存的安全和高效。
借用与引用
如果我们不想使用个变量都要这样「传来传去、接来接去」的话该怎么呢。Rust 还提供了另一种方式:借用。
& 符号就是 引用 ,它允许你使用「值」但不获取其「所有权」。
fn main() {
let str = String::from("Hello"); // str 生效
let len = takes_ownership(&str); // 通过 引用符号 将str 借用给 takes_ownership 函数
println!("{}", str); // str 依然生效,它还保留有所有权
}
fn takes_ownership(some_string: &String) -> usize {
// some_string.push_str(", World"); // 报错:引用值为不可修改
some_string.len()
} // some_string 虽然离开了作用域,但是它没有引用值的所有权,所以不会被释放
&str 语法创建了一个指向值 str 的引用,同时并没有拥有它的「所有权」。也因此,&str 只能使用这个「值」,当引用停止使用时,其指向的值也就不会被 drop。
而 takes_ownership 函数签名使用的 &String 也是同理,表示参数 some_string 的类型是一个引用。
Rust 中将以上这种,创建引用并使用的行为称为 借用 。
「借用」也有一些限制,比如说不允许将借用来的值进行修改。就如变量默认是不可变一样,引用值也是不可变的。
可变引用
我们可以想修改变量那样通过 mut 关键字来将一个变量转换为可变的。而引用则是要使用 &mut 关键字将引用值转换为可变的。
fn main() {
let mut s = String::from("hello"); // 被借用的值 也需要转换为 可变的
change(&mut s);
let r1 = &mut s;
let r2 = &mut s; // 报错:不能同时借用,
// r1 必须使用完 r2 才能再次借用
println!("{}, {}", r1, r2);
}
fn change(some_string: &mut String) { // &mut String 声明 some_string 是一个可变的String引用值
some_string.push_str(", world");
}
可变引用同样有限制:在同一时间,只能有一个对某一特定数据的可变引用。
这样的设计能很好的让 Rust 避免了在编译时出现「数据竞争」。
这三个行为同时发生就会造成「数据竞争」:
- 两个及以上指针同时访问同一数据;
- 至少有一个指针在执行写入操作;
- 没有同步数据访问的机制对数据进行保护。
数据竞争多数情况下会导致一些意想不到的问题,同时也难以定位和处理。Rust 可以说是从根源上制止了这个问题。
注意,在Rust中我们也不能同时拥有 「不可变引用」 和 「可变应用」,读取的同时又写入可能会互相影响。不过,我们同时拥有多个 「不可变引用」,因为只有读取的情况下是互不干扰的。
一个引用的作用域是从声明开始一直到最后一次使用。如果你在前一个 「不可变引用」 使用结束后再声明并使用 「可变引用」 这样也是没问题的,因为他们的作用域没有发生重叠。
悬垂指针
也叫迷途指针。当所指向的对象被释放或者回收后,但对该指针没有作任何的修改,以至于该指针依旧指向已回收的内存地址,此时该指针就被称为悬垂指针。
这几乎是所有拥有指针系统的编程语言都存在的问题;Rust 为保证指针永远不出现悬垂状态:当你拥有一些数据的引用,编译器确保数据不会在其引用之前离开作用域。
如果我们强行创建一个悬垂引用,那么在编译时就会直接报错:missing lifetime specifier